What is an SEO web crawler?
An SEO spider is a technical auditing tool used by SEO professionals to understand the website, collect information and find critical issues. The crawler works as a bot that visits every page on your website following commands provided by robots.txt file and then extracts data to bring data back to you.
This data helps SEO professionals and web developers build and maintain websites that search engines can easily crawl. An SEO-optimized website increases your chances of ranking organically on search engines.
Key considerations when choosing an SEO crawling tool
Below is a list of some key features we look for when comparing and assessing the different solutions available on the market. It’s worth mentioning that there is no one crawler that rules them all. The best technical SEO crawler would depend on the features you need and the size of the enterprise or clients you work with.
SEO crawlers should be able to analyze websites and provide a solution for the following core issues:
Canonical tags
Canonical tags are a powerful way to let search engines know which pages you want them to index. These tags will help in preventing duplicate content. Your tool must be able to identify canonicalized pages, pages without a canonical tag and unlinked canonical pages so that you can catch any misplacements early on.
Indexable and non-indexable pages
Indexable pages are pages that can be found, analyzed, and indexed by search engines.
Non-indexable pages are pages that are not indexed by search engines.
A spider should provide you with the indexability status of your URLs so as to ensure that you are not missing out on any ranking opportunities for pages that are not indexed (but you thought they were).
HTTP response status codes
Analyzing a website’s HTTP status code is an important part of a search engine optimization technical audit. HTTP status codes impact the indexing of websites, shedding light on whether URLs or content have been moved or if the server is facing any issues. Crawlers should provide a list of the status codes within your website structure, so you can then ensure that these codes are correct and rectify any errors when necessary.
The most common status codes that SEO specialists look out for include:
- 404 file not found: These are often referred to as broken links or dead links, meaning the server couldn’t find the requested source. If the page is important or brings in traffic, this should be addressed immediately.
- 301 moved permanently: This code indicates that the URL has permanently been moved to a different URL.
- 403 forbidden: This happens when a web server forbids the SEO bots request to view the page.
- 500 internal server error: This code refers to a situation in which there is a problem with the website’s server. Some common causes of a 500 error include permission error, 3rd party plug-in issue, misconfiguration of .htaccess file, or php memory limit.
- 200 okay: All good, crawling is successful and the server is able to send and receive data.
Inlinks and outlinks
- Inlinks will show the internal website links linking from one page to another.
- Outlinks will show all the links that are outgoing from a specific URL to other websites.
This is crucial when assessing your internal and external linking strategy, the anchors present on your website, as well as the status of your outgoing links (if they are “follow” or “no follow” — in other words, if are you passing your link juice to other websites).
Duplicate and Missing H1s
Pages with a missing H1 tag represent a missed optimization opportunity. H1 tags are considered to be ranking factors as they help users and search engines understand what content to expect from your page.
Meta descriptions
Having a list of pages with either missing or duplicate meta descriptions on the website is also very important. Meta descriptions are HTML tags that describe the content of a page. This description shows up on search engine result pages under the title and URL.
The SEO spider should also be able to provide you with the number of characters present in the meta descriptions, so you can ensure they are within the character limit of 140-160.
It’s worth mentioning that although meta descriptions are not a direct ranking factor for SEO, they do make up most of the real estate of your search result and also encourage users to click on your link. This will in return enhance both your website’s click through rate and traffic, which ultimately factor into the ranking algorithm.

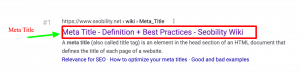
Meta titles
Tools should be able to display a list of URLs with either missing or duplicate meta titles. Meta title or title tag is the text that is displayed on both the search engine result page and the browser’s page title. Meta titles are considered to be direct ranking factors used by Google to judge the relevance of a webpage to a search query. That is why meta titles are a key place to integrate keywords. This high impact low effort tag is considered a low-hanging fruit among SEO specialists.
Hreflang tags
Hreflang tags are important for multi-language websites. The hreflang tag signals to Google about which language you are using for a specific page. This way Google can show the right page for users searching in a specific language. A crawler should be able to display the pages with hreflang tags and point out any issues relevant to the tags such as missing return links, incorrect language and region codes, missing x-default etc.

Detect Structured Data (Schema Mark Up)
Schema markups are another way for search engines to understand and classify content. Schema markups are embedded in the website code. Crawlers should provide you with an analysis of your website’s structured data and the type of schemas present on your web pages. This will help you identify any incorrect markups or missing opportunities for rich snippets.
Mixed content
Crawlers should show HTML pages that have resources loaded via an insecure HTTP connection. Mixed HTTPs and HTTP content (hence the name) on the same page weakens the security of the page and makes the website susceptible to attackers. More and more browsers are blocking mixed content.
Ability to crawl Javascript websites
As more and more websites are using Javascript. SEO technical crawlers are trying to adapt and support Javascript crawling. If this is an important feature (based on the websites you plan on crawling), you need to ensure that your crawler can enable this feature.
SEO crawlers and content analysis
Shallow content
SEO content that does not add or give value to visitors is considered shallow content. Every day thousands of content pieces are being published on the internet. For your content to rank, you need to provide users with the best and most relevant value and information among all the other thousands of websites available.
Duplicate content
A crawler should be able to provide you with links to pages with similar content. Duplicate content is identical content or almost identical content that appears on different pages on the website. This causes some confusion for Google as they don’t know which version to include or rank, so page rankings get diluted. Also, Google is keen on ranking pages with distinct information, and duplicate content shows the exact opposite of that.
Crawler and adjustable settings
Scan depth
Limit the number of crawled URLs either to a one-page crawl or a list of provided URLs. This is great for when you want to crawl only blogs for example. It saves time and resources.
Exclusion of domain or subdomain
Limit the crawler from scanning a specific domain or subdomain on the website. The purpose of this is to save time and or resources.
Advanced filtering
When you want to filter specific URLs, titles, pages, resource types or any metric, having multi-layer filtering is a time saver. This is even more important for advanced SEO specialists who know their way around SEO metrics and want a crawler they can manipulate data on to showcase exactly what they need. Ex.: Canonical URLs with duplicate meta titles and hreflang tags.
Collaboration
Ability to share crawl with another user
It’s pretty common to have more than one person working on the same project, so having the ability to share your audit will enhance collaboration and productivity.
Dashboards
A dashboard that can show specific areas or issues that need attention, the scores or overall health of these areas, and the individual errors with an explanation behind them.

Sitebulb Audit Dashboard
Integration with Google Analytics and Google Search Console and Page Speed insights
Integration with these platforms allows for a holistic view of all metrics in one location instead of having to view data separately with you and your team.
Types of crawlers
It’s important to understand the different types of crawlers available on the market.
Desktop crawlers
Desktop crawlers are technical crawlers that are installed on your desktop. They are generally cheaper than cloud-based crawlers and for a reason. These local crawlers are bound by the space and memory of the computer or device they are installed on, limiting the number of URLs you can ultimately crawl.
Cloud-based crawlers
Cloud-based web crawlers reside in the cloud. Users do not need to install and host the programs on their devices. They are a great option for online collaboration but come at a higher price tag than desktop crawlers.
SEO tools compared
Before making a purchase, we narrowed down our search to test four SEO crawlers. These four were chosen based on our needs as an agency, our clients and reviews from other SEO specialists and experts.
Screaming Frog
Screaming Frog is one of the most popular crawlers on the market because it’s a pioneer in the industry. In addition, it includes almost every technical SEO feature required.
How much does Screaming Frog cost?
Screaming Frog provides a free version where you can download the software and crawl up to 500 URLs. The paid version provides unlimited URLs (limited by your device storage and memory) and more features.
Cost: $209 USD/year per license.
Pros:
- Generation of XML sitemaps
- Integrates with Google Analytics and Google Search Console
- Data is easy to export
- Crawls can be saved
Cons:
- Lack of data visualization
- Limited filtering options
- The interface is Excel-like
- Not beginner-friendly. Unlike other SEO crawlers, it does not point out the SEO issues or have scores on a dashboard
Sitebulb

What we love most about Sitebulb is that it combined the best of both worlds: desktop crawlers (no limits, highly customizable) and cloud-based crawlers (data visualization and cross-collaboration). One of the notable features of Site Bulbb is the crawl maps, which are able to provide an overview of your website’s structure, check for orphan pages and discover the flow of internal links.
How much does Site Bulb cost?
Site Bulb subscription starts from 13.5 USD/month. It also offers a fully-featured 14-day free trial to the platform.
Pros:
- Multi-layer filtering
- Audit scores. Site Bulb provides a score out of 100 for every aspect of your website
- Ability to integrate with Google Sheets, Google Analytics and Google Search Console
- Crawl comparison feature (it is the only desktop crawler with this feature on the market). This is a great feature that allows you to demonstrate improvements graphically from crawl to crawl
- Detection of JS and CSS problems
- Crawl scheduling
- Hint systems that show where you have critical issues that need attention
Cons:
- It runs on your system resources
- It can only do one crawl at a time
Ryte

Ryte is a multi-solutions platform offering an all-inclusive cloud-based solution for website user experience.
Pros:
- Robots txt Monitoring. You can monitor to see if any changes were made to your robots.txt file and catch any mistakes early on
- Slack notifications. You can be notified in Slack or via email when unexpected changes occur
- Advanced Crawling. You can adjust settings and asses with Javascript rendering and mobile viewport
Cons:
- UX is not stable
Botify

Some of the most prominent companies in the world use this tool, including Expedia, L’Oreal and Glassdoor. Botify is an enterprise-level crawler and one of the first integrated suites of apps made for SEO stakeholders.
Pros:
- Filtering reports and dashboards by segments
- Advanced analytics
- Chrome Botify plugin. The Botify Chrome plugin displays HTTP codes, page depth, incoming links, outgoing links, canonicals and visits volume on webpages you are browsing
- Custom Extraction Rules. HTML extract allows you to extract a custom field from the source code of your pages
- Enterprise Advanced Reports allows you to export unlimited data in customer reports
Cons:
- Botify does not disclose pricing information on its website
- The platform is not intuitive, and there is a learning curve that comes with this solution
- The product is complex and includes various filters and features
More SEO tools
Other crawlers in the market that also have an excellent reputation among SEO professionals include:
Deep crawl is an enterprise-grade platform that provides on-page SEO recommendations and backlink tracking. The tool has a responsive modern interface that integrates with Google Analytics and Google Search Console.
Among desktop crawlers, Netpeak is said to have the best optimal ram consumption. They also have great customer support where questions can be addressed directly via online chat on their website. One drawback is currently they do not support iOS OS. We contacted their customer service, and they mentioned that this should be available in the next 3 months.
Oncrawl is great for building custom dashboards and boasts excellent hreflang reporting.
Website Auditor’s most prominent features include website structure visualization and content analysis.
Although new on the market, they are making a name for themselves in the world of SEO crawlers. One of their key features are graphs and data tables. They are also one of the most affordable crawlers on the market.
Siteliner is free for most users which makes it a great tool for beginners. One of their main strengths is their duplicate content checker feature, which scans your website for similar content.
Comparing my two favorite SEO crawlers [comparison screenshots and steps included]
Screaming Frog vs SiteBulb
This is a side by side comparison between Screaming Frog and Sitebulb, which are among the top-rated desktop crawlers on the market.
To be able to follow along with these scenarios, ensure you have a project set up and crawled on each of them.
Here are the scenarios:
1. Find schema structure issues
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | Click on Structured Data on the left navigation bar. | Click on Structured Data tab. |
| Step 2 | On the top navigation press on schema. | On the drop down menye select Validation Errors. |
| Step 3 | You can export a list of URLS with schema entities that include errors. | Export pages with schema validations errors. |

Structured Data Audit Sitebulb

Structured Data Screaming Frog
2. Find images without next gen formats, such as Webp
Webp image format was created by Google to replace traditional image formats such as JPEG and PNG. Webp images offer better loading time and are preferred by Google crawlers.
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | Under URL reports on top navigation tab click on images and then on image URL’s. | Go to images tab and ensure filter is set to All |
| Step 2 | On the top navigation press on schema. | Click on search tab |
| Step 3 | Click on advanced filter under the top tabs | Select content type , does not contain, and add webp in the empty cell. |
| Step 4 | Select Mime-Type as the filtered column and select does not contain and type “webp” on the empty cell. | This will render all image URL’s that are not in webp format. |
| Step 5 | This should provide you with a list of all images that are not in WEBP format. |
This is a great example of the filtering options available on these crawlers.

Sitebulb Image URLs

SiteBulb Advanced Filtering

Screaming Frog All Images

Screaming Frog Advanced table search

Screaming Frog Webp images
3. Find assets that are wasting code
This feature will help identify all pages where code is being loaded and not used. This will enable users to clean up these pages to include only the code that is required, which will reduce page size and decrease load time.
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | Click on the Code Coverage tab on the left. | This feature is not available on screaming frog trial version. |
| Step 2 | You will have the option to see the wasted coverage for both CSS and Javascript. |
Sitebulb offers this feature, which is not prominent among all crawlers. You can actually find where you have dead and unused code on the website.

Wasting Code audit Sitebulb
4. Find images that are missing alt text
Google is not able to view images, so alt text is a way to communicate with search engine crawlers and let them know what the image is. It is also an opportunity to optimize for keywords and attempt to rank for them. Finally, alt text improves site accessibility by enabling visually impaired users to better understand an image.
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | Click on URL reports, go to images and select images with missing alt text | Click on the images tab |
| Step 2 | for both CSS and Javascript. | Under filter tool, filter URLs Missing Alt Text |

Missing Alt Text Sitebulb

Missing Alt Text Screaming Frog
5. Find URLs with mixed content
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | Go to security tab under audit overview | Go to security tab |
| Step 2 | Go to URL explorer in top navigation. | Filter to Mixed content |
| Step 3 | Under security tab select “Loads Mixed Content” | A list of all URLs with mixed content |

Mixed Content Screaming Frog

Mixed Content Sitebulb
6. Find URLs without H1
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | Select URL Explorer tab | Select H1 tab |
| Step 2 | Click on Content | Filter by missing. |
| Step 3 | Click on H1 is missing |

Missing H1 Sitebulb

Missing H1 Screaming Frog
7. Find URLs with 404 errors
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | Select URL Explorer tab | Click on Response Codes tab |
| Step 2 | Click on Internal and select Broken | Filter by Client Error (4xx) |

Broken Links Sitebulb

404 Errors Screaming Frog
8. Find URLs with incorrect formatting
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | Click on URL reports, URLs, ALl URLs | Click on URL Tab |
| Step 2 | Go to Adv. filter Click on URL contains non-ASII characters URL contains Non-Lowercase Characters URL contains repetitive elements. URL contains space characters | Filter by the different formatting errors Non ASCII Characters Underscores Uppercase Multiple Slashes Repetitve Path Contains Space |

URL’s with incorrect formatting Sitebulb

URL contains incorrect characters Sitebulb

Incorrect Formatting URL Screaming Frog
9. Find orphan URLs
Orphan URLs are pages that are not linked to any page from the website. This means that crawlers cannot follow the page from another link, which makes indexing these pages harder. Identifying the URLs and linking back to them would solve this issue.
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | Click on URL explorer tab | Go to Sitemaps tab |
| Step 2 | Go to Internal and select orphaned. | Filter by “Orphan URLs” |

Orphan URL Sitebulb

Orphan URL Screaming Frog
10. Find URLs with hreflang tags
| Steps | Site Bulb | Screaming frog |
|---|---|---|
| Step 1 | This feature is triggered as a hint | Click on Hreflang tab |
| Step 2 | Filter “contains hreflang” |

Contains Hreflang Screaming Frog
Bonus Scenarios: Below are four advanced technical issues found via Sitebulb
Internal redirected URLs
These are URLs that are an internal redirect to another URL, basically redirecting a redirect, which makes for an extra step for search engine crawlers, resulting in a bad overall experience.
| Steps | Site Bulb |
|---|---|
| Step 1 | This will pop up as an error under the name “Internal redirected URL’s, go to view URLs |
| Step 2 | You will get a view of all internal redirect urls with the parent URL and the redirected URL on the page. |


URL Redirected redirects Sitebulb
Defer off screen images (images that are not lazy-loaded)
This is a hint provided by Sitebulb and lists out internal URLs that contain images that are not lazy-loaded. Once a browser loads a page, all resources (not deferred) will also be loaded. This increases the “Time to interactive,” which is the amount of time it takes for a page to be fully interactive.
| Steps | Site Bulb |
|---|---|
| Step 1 | A Hint will be triggered named “Defer offscreen images” |
| Step 2 | A list of pages will populate thatr include images without lazy loading. |


Images with no lazy loading Sitebulb
Reduce Server Response Times
Hint is triggered for URLs that TTFB (Time-to-First-Byte) more than 600 m. TTFB is the time it takes for a browser to receive the first byte of data from the website’s server. This is important because the longer it takes, the longer the page takes to load. This affects both the page’s core web vitals and user experience, both of which are important ranking factors.

Server response times Sitebulb
Missing Viewport
A viewport tag tells the browser how to control the page’s scaling and dimensions. This is especially important for when viewing pages on different devices (a mobile screen is smaller than a laptop screen).
| Steps | Site Bulb |
|---|---|
| Step 1 | Go to URL reports , images, all image URL’s |
| Step 2 | Add/remove column and choose missing viewport. |

Find images with missing viewport

Advanced Filtering Image missing viewport Sitebulb

Images Missing Viewport Sitebulb
To sum it up
Before making your decision, request a trial version and test a couple of different tools. The trial will give you a hands-on feel of what’s a priority to you and your enterprise.
Remember that there isn’t a perfect crawler out there. There is a crawler that is best for you, your clients and your budget.
The perfect SEO spider will portray the general SEO technical issues, including metas, headers, broken links, orphan pages, mixed content etc. The platform should enable you to adjust crawl settings and provide advanced filtering. Content is an integral part of SEO and having a crawler that can point out pages with shallow or duplicate content is an asset. And, finally, ensure the crawler has features that will enable you to integrate with GSC and GA and collaborate with your team.
Ensure the tool has the features you need and is not limited by a specific package. SEO crawlers, when used correctly, are valuable assets to SEO professionals. These tools should enable you to improve your site’s health, speed and accessibility — all important pillars to organic rankings and search performance.
If you have any questions or need help with Enterprise SEO, contact us to see if we’re a fit.